LLMOps — Part 2 : Data Preparation
This is the second part of my LLMOps series. In my previous article, we had briefly discussed about the workflow of LLMOps.
The entire series is divided into 4 parts : The Introduction, Data Preparation, Automation and Orchestration with pipelines, and the last part being Prediction, prompts, safety.
Link to my previous article : https://medium.com/@tulsipatro29/llmops-part-1-the-introduction-81fa77999f44
One of the key steps in LLM is dealing with a lots of text data.
In this article we will learn how to extract text from a Data warehouse dealing with data that is too large in memory using sql & then modify the data to tune the model to be more task specific.
A Data warehouse is a central repository for storing and analyzing large amount of data from various sources. It is used to gain insights & make informed decisions. You can take your data from application databases & bring it to your warehouse and make it available for your teams to use it.
In this case, we will be using BigQuery. BigQuery is a data warehouse and is serverless. We don’t need to manage servers, plus it allows us to use sql query.

SQL queries are used as they can processes large amounts of data, making it a good choice for cases requiring high performance. It is great with cleaning while doing data preparation.
Steps for Data Preparation
First, we need to start with Authentication, where we load our credentials which will help in the authentication and then set up the region.
Then we will import the vertex AI library and initialize the vertex AI using project id, location and credentials.

To interact with the data warehouse, we again have to initialize a library called ‘Big Query’ client. We import ‘Big Query’ and then initialize the project.
The dataset used in this is the ‘Stack overflow public dataset’. The dataset has tables with data. Tables in the dataset are organized as collection of data.
Let’s explore the dataset with SQL and let’s select the table names.

We will use the client initialized. Big Query Client takes in the SQL query and sends it to the api of the data warehouse and will return the dataset. Then we print each row which is a table name so that we can see which tables are available.

We are going to perform PEFT & supervised fine tuning, so we want to create a dataset that has a question & an answer.
I. DATA RETRIEVAL
Let’s retrieve some data from the table by fetching some data from the data warehouse and visualize it. We will load the result of the query in a Pandas dataframe.

From this query, we will get all the data & will load it using pandas & then execute the query again.
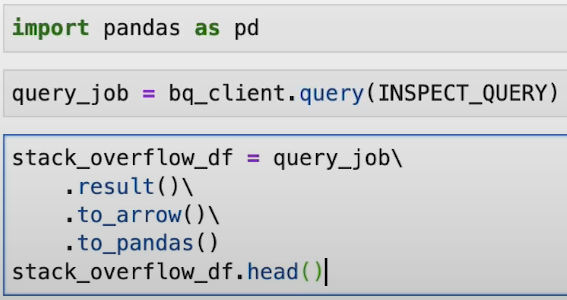
This approach allows to see the results of the query job in a data frame.
Here, we can see all the columns of the data.

II. DEALING WITH LARGE DATASETS
LLMs are trained on large datasets that don’t fit into memory.
Large data can definitely be added to Data warehouse but it becomes difficult to add them into your local machine or virtual machine.
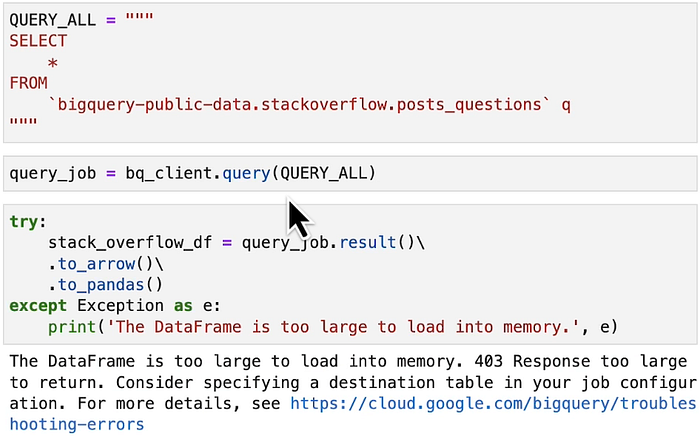
How are we going to deal with such large dataset ?
Where does the data live ?
With large datasets, we can get issues with memory.
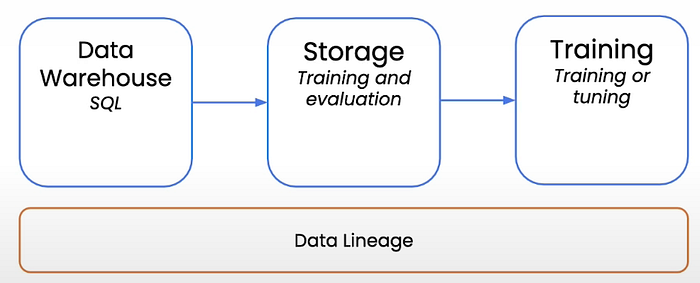
Data sits in a Data warehouse & when you have large tables and we want to do things like ‘joining’ or ‘filtering’, it’s best to do the processing through sql in your data warehouse.
In order to deal with large datasets, instead of exporting all of the data and then doing the work there are several things which can be done.
First thing is, once you have selected the data & you know what you want to use for training, you can export your results to SSD (solid state drive) or cloud storage bucket.
During tuning or training, your data can be accessed quickly with cloud. Reading this data can be done faster when using SSD or a cloud storage bucket. You also want to make sure your accelerators or GPUs are not under utilized.
To keep track of the data lineage, you want to know where your data comes from and which transformations it has gone through.
Solution for working with large data is to optimize your query to save resources & time.

We now have a dataset with questions and answers.
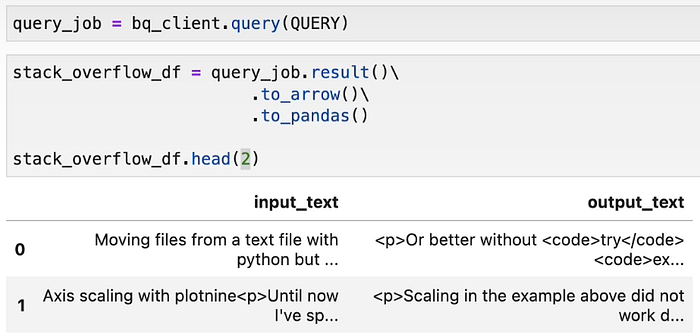
III. FINETUNING LLMs
Adding instructions is basically guiding the model to do what and what not, as we want the LLM to answer the questions properly.
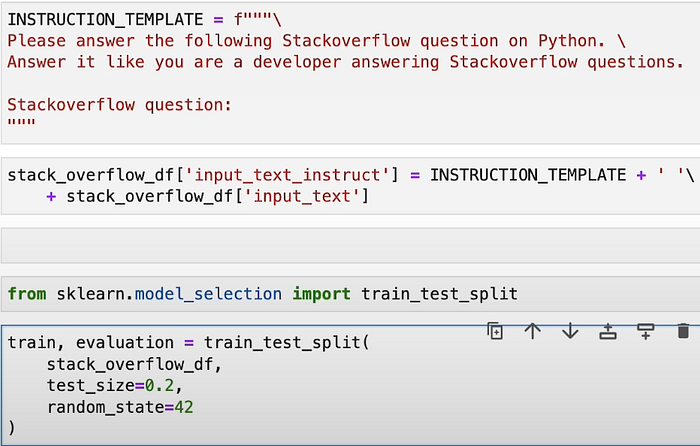
We can’t calculate Accuracy, as we have text data which is very ambiguous.
Large files in a data warehouse has to be stored in SSD or any cloud storage so that it can read it efficiently during training or tuning.
IV. File format for training & evaluation data

V. Versioning Artifacts
When building MLOps workflow, its important to think about versioning your artifacts, i.e. keeping a track of the artifacts.
It allows for reproducibility, traceability, and maintainability of machine learning models. So, its important to get the timestamp.
VI. Generate a file for Training data
Best way is to write your file into a SSD environment or cloud bucket if we have large no. of files.
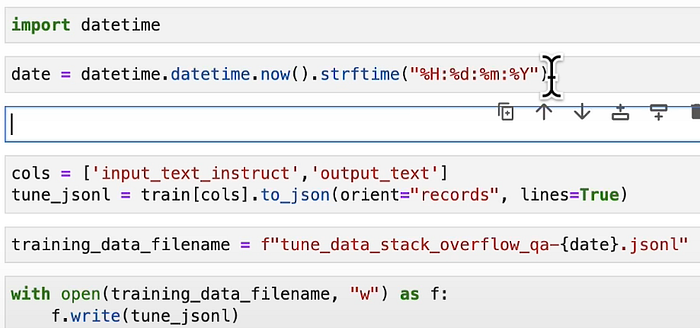
The code above genertes a jsonl file for the training dataset. Similarly, we can create another jsonl file for evaluation set.
So, to summarize we have successfully learnt to access the data from the data warehouse and then retrieve the data as dataframe. Additionally, preparing the training and evaluationa file.
The upcoming article would describe the establishment of the pipelines.
Stay Tuned!
Happy Reading!
